Write-up FCSC 2024 : Kraken
2024-04-14 22:00 +0200I - Intro
Kraken looks like a fairly complex reversing challenge. We are given a few more files at the start in addition
to the binary, the most important one being a Dockerfile that sets up a specific environement required to run
the program easily.
A quick look at this Dockerfile will tease us about what we are about to endure:
FROM debian:bookworm-slim
WORKDIR /build
RUN echo "deb-src http://http.us.debian.org/debian bookworm main" >> /etc/apt/sources.list && \
apt-get update && \
apt-get install -qy --no-install-recommends \
dpkg-dev \
build-essential \
fakeroot \
devscripts \
clinfo \
llvm-spirv-15 \
ocl-icd-libopencl1 && \
# Dependencies for pocl compilation \
apt-get source pocl-opencl-icd && \
apt-get build-dep -qy pocl-opencl-icd && \
apt-get clean && \
rm -rf /var/lib/apt/lists/ && \
cd pocl-3.1 && \
DEB_BUILD_OPTIONS="notest nocheck nodocs" debuild -us -uc && \
cd .. && \
dpkg -i *.deb
WORKDIR /app
Ugh… llvm-spirv-15, pocl-opencl-icd, it sounds like we are about to see some GPU shenanigans.
II - First look and extracting the SPIR-V code
First of all we will import the main ELF binary in Ghidra. It’s a x86-64 linux program,
we can fairly easily see that the main() will expect a file path to be passed as an arguement.
The file will be opened and entierly read in memory.
Once it’s loaded a few headers are checked, a magic is looked up and it gives us a hint that
the file should be a binary netpbm image as
they are recognizable by their first line being P6.
This is the easiest image format you can imagine, a simple text header specifying the size of the image and the depth of the colors, then you just yeet the pixels in binary RGB from left to right, top to bottom.
The size of the image is checked to be at least 0x100000 pixels long with 8 bits per colors.
There are a few oddities when the file is parsed, maybe I was doing something wrong but I only managed to get the parser to accept P6 files with a comment in the header:
P6
#~
1024 1024
255
[pixels]
A simple function then splits the channels in three different buffers and…
if (split_channels(file + hdr_len, len, r, g, b) != 0) {
goto out;
}
fprintf(stdout, "[+] OK: loaded %s\n", file_name);
free(file);
// [...]
sha256_init(state);
sha256_update(state, "UNLEASH_THE_KRAKEN_", 0x13);
sha256_update(state, r, 0x100000);
sha256_update(state, g, 0x100000);
sha256_update(state, b, 0x100000);
sha256_final(state, hash);
r = memcmp(hash, "\x98\x58\xe1\x8b\x40\xae\x29\x0a\x05\x30\x86\xca\x3a\x39\xfd\x2f"
"\xfc\x9f\x31\x99\x4a\x37\xf7\x7d\x3c\xf6\x82\xb6\xaa\xeb\x58\x31", 32) == 0;
// (the memcmp is unrolled but that's not the point)
Yep sure, so the solution is obviously to crack the SHA256 hash on about 3MiB of data! :)
More seriously it’s pretty surprising to see the challenge done this way: its fairly common in reversing challenges to have a crackable check that you are supposed to understand and reverse and a second “cryptographically secure” check that will make sure you provided the unique valid input before showing the flag.
Here the situation is reversed, the unbreakable check is done before, thus we need to patch the binary to be able to go further and analyse dynamically what’s happening during the part we really need to understand.
The patch is the most obvious one, you just change the following jnz in a bunch of nops.
Now let’s not spend 15 years trying to understand how the binary works and how it sets up all the OpenCL context:
we were spoiled by the Dockerfile that most of the challenge will probably be about reversing some SPIR-V code,
let’s just follow some intresting x-refs like the import clCreateProgramWithIL:
do {
prg1[i - 1] = KEYSTREAM[(i - 1) & 0xff] ^ PROG_1[i - 1];
prg1[i] = KEYSTREAM[i & 0xff] ^ PROG_1[i];
i = i + 2;
} while (i < 0x2780);
PROG_1_ID = clCreateProgramWithIL(context, prg1, 0x2780, &err);
And this is repeated for 3 different programs, this is a simple XOR cipher that can be decrypted with a few lines of python:
f = open("kraken", "rb")
f.seek(0x6430)
keystream = f.read(0x100)
f.seek(0x6530)
prog1 = f.read(0x2780)
prog2 = f.read(0x2cc4)
f.read(12)
prog3 = f.read(0x14dc)
f.close()
for (n, prog) in enumerate((prog1, prog2, prog3)):
prog_dec = []
for (i, x) in enumerate(prog):
prog_dec.append(x ^ keystream[i % 0x100])
open("prog%d.spirv" % (n+1), "wb").write(bytes(prog_dec))
$ file *.spirv
prog1.spirv: Khronos SPIR-V binary, little-endian, version 0x010400, generator 0x06000e
prog2.spirv: Khronos SPIR-V binary, little-endian, version 0x010400, generator 0x06000e
prog3.spirv: Khronos SPIR-V binary, little-endian, version 0x010000, generator 0x06000e
Poking around a little bit in the binary we can easily see that each channels will be treated separately before being checked against an hardcoded expected output.
III - Reversing the SPIR-V code
The first obvious idea is to disassemble the SPIR-V bytecode, a quick Google search later we learn that we
can use spirv-dis from the Vulkan SDK.
In the end I mostly used the SPIR-V Visualizer on Khronos website. As the SPIR-V IL is a static single-assignment IR it’s very easy to compile but very hard for a human to keep track in what’s happening: a “variable” is only used once and you end up with things like “%1337 is xorred with %42 which is the mod of %99 and %6666, %99 is loaded from %76 at index %12…”.
This visualizer helps you see the expressions in the form of a tree and you can easily click around to see what values depend on what.
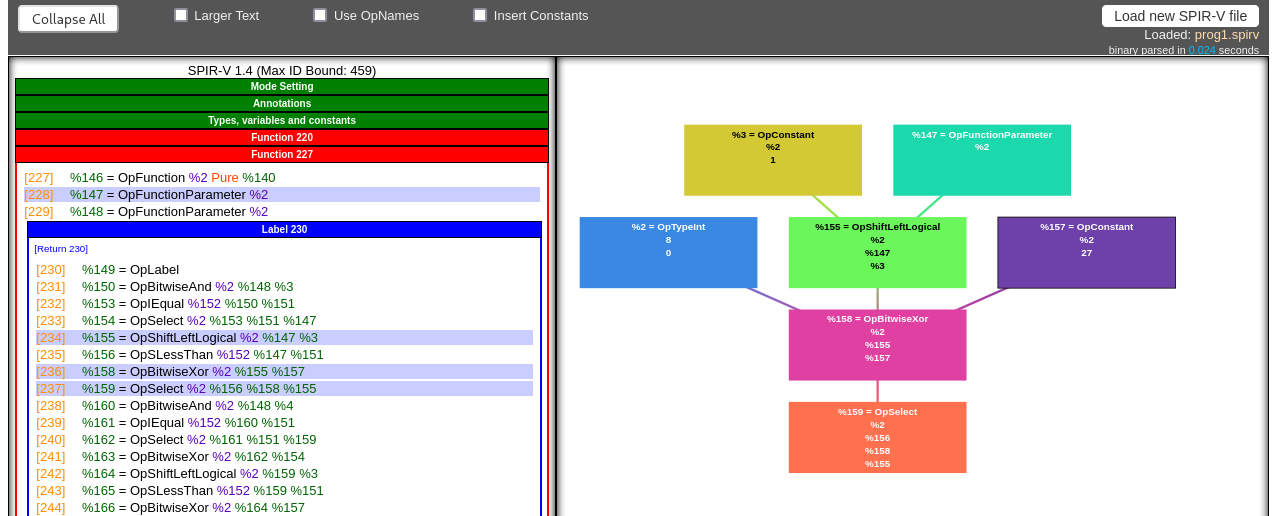
It really helped me understanding what was happening in each exported functions (known as “kernels”) of each programs. After looking around for a bit I managed to understand the following:
cinprog1loads a pixel, applyzand saves it backbinprog1loads pixels in a loop with a body very similar tozbinprog2is just a buch of s-boxesa,bandcinprog3look similar: they apply some operation between two images, this can be- add:
out[i] = img0[i] + img1[i] - sub:
out[i] = img0[i] - img1[i] - xor:
out[i] = img0[i] ^ img1[i] - rotate left:
out[i] = img0[i] rol img1[i] - using the other image as an index:
out[img1[i]] = img0[i]
- add:
IV - Instrumenting the transormations
After having a rough idea of what the SPIR-V code was used for I wanted to track when it was used. As I guessed the “hard” part of the challenge would mostly be about understanding what the SPIR-V was doing, I wanted to go the easy way and just log which kernel was called and with what input as to not spend too much time reversing the main binary.
For that I simply followed the x-refs of clFinish, it is used to wait for a OpenCL job to end. It’s only used in a single function
that is responsible to setup a job, copy the input buffers and launch the actual job.
It was a pretty tedious process as the structure is quite big and the OpenCL API is not that intuitive. I have some (very limited) background experience with OpenGL, as it has some common ideas it helped a little.
In the end I wrote the following code, intended to be injected as a shared object using LD_PRELOAD:
#include <assert.h>
#include <stdlib.h>
#include <stdio.h>
#include <sys/mman.h>
#include <stdint.h>
#include <string.h>
#include <unistd.h>
typedef unsigned char undefined;
typedef unsigned char byte;
typedef unsigned char dwfenc;
typedef unsigned int dword;
typedef unsigned long qword;
typedef unsigned int uint;
typedef unsigned long ulong;
typedef unsigned char undefined1;
typedef unsigned int undefined4;
typedef unsigned long undefined8;
typedef unsigned short ushort;
typedef unsigned short word;
typedef struct cl_program cl_program;
__attribute__((packed)) struct cl_program {
undefined8 context;
undefined8 dev_id;
undefined8 program;
char *kernel_name;
uint work_dim;
undefined4 _pad2;
ulong dims[20];
uint n_write_bufs;
uint write_buf_is_kernel_arg[20];
uint write_buf_len[20];
undefined4 _pad0;
void *write_buf_ptr[20];
uint n_read_bufs;
uint read_buf_len[20];
undefined4 _pad1;
void *read_buf_ptr[20];
};
static_assert(sizeof(cl_program) == 0x308);
#define run_cl_program_start_addr 0x555555555d80
#define run_cl_program_end_addr 0x555555556188
uint64_t* PROG_1 = (void*)0x555555863130;
uint64_t* PROG_2 = (void*)0x555555863140;
uint64_t* PROG_3 = (void*)0x555555863150;
static const cl_program* cur_prg = NULL;
static size_t cur_mul_size = 1;
void run_cl_program_trace(const cl_program* prg) {
if (prg->program == *PROG_1) {
printf("prg:1");
} else if (prg->program == *PROG_2) {
printf("prg:2");
} else if (prg->program == *PROG_3) {
printf("prg:3");
} else {
printf("prg:0x%zx", prg->program);
}
printf(" krnl=%s\n", prg->kernel_name);
printf("%u dims ", prg->work_dim);
size_t mul_size = 1;
for (size_t i = 0; i < prg->work_dim; i++) {
mul_size *= prg->dims[i];
printf("%u", prg->dims[i]);
if (i < prg->work_dim-1) {
putc(' ', stdout);
}
}
cur_mul_size = mul_size;
printf("\n");
printf("%u wbuf %u rbuf\n", prg->n_write_bufs, prg->n_read_bufs);
for (size_t i = 0; i < prg->n_write_bufs; i++) {
if (prg->write_buf_is_kernel_arg[i]) {
printf("w[%zu] = ", i);
for (size_t j = 0; j < prg->write_buf_len[i]; j++) {
printf("%02x", ((uint8_t*)prg->write_buf_ptr[i])[j]);
}
printf("\n");
} else {
printf("w[%zu] = ", i);
for (size_t j = 0; j < prg->write_buf_len[i] * mul_size; j++) {
printf("%02x", ((uint8_t*)prg->write_buf_ptr[i])[j]);
}
printf("\n");
}
}
cur_prg = prg;
}
void run_cl_program_end_trace(void) {
if (cur_prg == NULL) {
fprintf(stderr, "oopsie\n");
abort();
}
for (size_t i = 0; i < cur_prg->n_read_bufs; i++) {
printf("r[%zu] = ", i);
for (size_t j = 0; j < cur_prg->read_buf_len[i] * cur_mul_size; j++) {
printf("%02x", ((uint8_t*)cur_prg->read_buf_ptr[i])[j]);
}
printf("\n");
}
cur_prg = NULL;
printf("===\n");
}
__attribute__((naked)) void run_cl_program_hook(void) {
asm("push %rdi;"
"call run_cl_program_trace;"
"pop %rdi;"
"push %rbp;"
"push %r15;"
"push %r14;"
"push %r13;"
"push %r12;"
"push %rbx;"
"sub $0x38, %rsp;"
"mov $0x555555555d8e, %rax;"
"jmp *%rax;");
}
__attribute__((naked)) void run_cl_program_end_hook(void) {
asm("pop %rbx;"
"pop %r12;"
"pop %r13;"
"pop %r14;"
"pop %r15;"
"pop %rbp;"
"push %rax;"
"call run_cl_program_end_trace;"
"pop %rax;"
"ret;");
}
__attribute__((constructor)) void instr_init(int argc, char** argv) {
assert(argc >= 1);
if (strcmp(argv[0], "./kraken-patched") != 0) {
// We check that we are running attached to `kraken-patched` as we will
// also be preloaded with `gdbserver`
return;
}
int ret = mprotect((void*)0x555555555000, 0x5000, PROT_READ|PROT_WRITE|PROT_EXEC);
if (ret < 0) {
perror("mprotect");
_exit(1);
}
{
uint8_t code[] = {
0x48, 0xb8, 0xde, 0xad, 0xc0, 0xde, 0xde, 0xad, 0xc0, 0xde, // movabs rax, imm64
0xff, 0xe0, // jmp rax
};
*(uint64_t*)(code + 2) = (uint64_t)run_cl_program_hook;
memcpy((void*)run_cl_program_start_addr, code, sizeof(code));
}
{
uint8_t code[] = {
0x48, 0xbb, 0xde, 0xad, 0xc0, 0xde, 0xde, 0xad, 0xc0, 0xde, // movabs rbx, imm64
0xff, 0xe3, // jmp rbx
};
*(uint64_t*)(code + 2) = (uint64_t)run_cl_program_end_hook;
memcpy((void*)run_cl_program_end_addr, code, sizeof(code));
}
ret = mprotect((void*)0x555555555000, 0x5000, PROT_READ|PROT_EXEC);
if (ret < 0) {
perror("mprotect");
_exit(1);
}
}
As there isn’t enough free space at the beginning and end of the function I was hooking, I manualy copied its prologue and epilogue in my own code.
You might have noticed that all the addresses are hardcoded in the 0x55555... range, this is because to simplify the process
I was running the program within GDB. However as explained in the introduction, the program is running in a Docker container.
To make it more pleasant to use my host GDB, I used a gdbserver with the --disable-randomization option to make sure ASLR
is disabled. However this requires the process to change personality with personality(ADDR_NO_RANDOMIZE) and this is only
allowed in privileged contaiers1.
With this logging I was able to get a pretty rough idea of when each OpenCL program was called and with which inputs.
Now I needed to understand some functions I was missing, for that I wanted to run them with my own inputs. I looked up
solutions to run SPIR-V code on a CPU easily: the “official” solution is to convert SPIR-V IR to LLVM IR before compiling it
for your host CPU. If you are a very attentive reader you might have already noticed in the Dockerfile that we installed
some packages related to LLVM, this is exactly why it’s required: most of the time we run OpenCL programs on dedicated
hardware (such as a GPU) but for making the challenge easier to run the authors provided us with a container already configured
to run everything on the CPU.
Now the goal was to use this feature for ourselves to easily try different inputs. For that you can use
llvm-spirv, it will produce a LLVM bitcode file that can be
linked with other LLVM bitcode.
I simply used clang to compile a bit of C++ that will run the SPIR-V program with a few inputs, for example this is
how I looked at the output produced by b() in the program 1:
#include <cstdint>
#include <cstdio>
extern "C" void b(...);
extern "C" void c(...);
static int global_id[16] = {0};
unsigned int get_global_id(unsigned int d) {
return global_id[d];
}
int main(void) {
uint8_t w0[] = {1, 1, 1, 1};
uint8_t w1[] = {1, 1, 1, 1};
uint8_t r0[4] = {0};
for (size_t i = 0; i < 2; i++) {
for (size_t j = 0; j < 2; j++) {
global_id[0] = i;
global_id[1] = j;
b(&w0, &w1, 2, 2, &r0);
printf("%02x %02x\n", r0[0], r0[1]);
printf("%02x %02x\n", r0[2], r0[3]);
printf("\n");
}
}
}
Notice that we are using C++ here, this is because the bitcode generated by llvm-spirv expects to be linked with an
object containing the function get_global_id that should return the ID of the current workload in a specific dimension.
However the name of the function is using C++ mangling, the easiest way to deal with it was simply to write the main driving
code in C++. The name of the exported functions were not mangled, this is why we use export "C" in front of their declaration.
I tried to look at the result produced by the different functions and I even tried to generate all the possible values for functions with a single 8 bit integer as parameter, but I still couldn’t make sense of some of them.
If only we had a way to look into what this binary we just built ourselve was doing… wait a second.
V - Cheating and making this a x86 challenge with LLVM
We clang -O0 -g all of those nicely provided LLVM bitcodes, import them into Ghidra and we get a nice, easy to understand
decompilation for each function!
In the end I was able to identify what all of the functions were doing:
cinprog1apply a power in GF(256) on each input pixel with a catch- the result is xored with
0xaband they are offseted from the input matrix bypelements, withpthe index in the array of allowed powers
- the result is xored with
binprog1does matrix multiplication in GF(256) with another catch- each element of the output matrix is added with
x + y
- each element of the output matrix is added with
binprog2is indeed a few s-boxesa,bandcinprog3are indeed applying the operations described earlier but with an important difference:ais working on 32 bit integersbis working on 16 bit integerscis working on 8 bit integers
It took a bit of time to understand that c and b of prog1 are doing multiplications in GF(256), as I previously tried to understand
what they were doing with the bruteforce approch. By looking at all the possible inputs I was able to understand that it was
“multiplication on 8 bits but it goes whack when overflowing”. In the end having the Ghidra decompilation realy helped as I was able
to Google “multiplication xor with 0x1b” to find it out.
Cross-referencing my results with the table used in AES helped to confirm it.
gid_y = get_global_id(0);
gid_x = get_global_id(1);
local_20 = 0;
local_19 = 0;
if (width != 0) {
local_20 = gid_y * width;
local_75 = 0;
i = 0;
do {
bVar1 = w0[i + local_20];
bVar2 = w1[i * height + gid_x];
local_7d = 0;
if ((bVar2 & 1) != 0) {
local_7d = bVar1;
}
local_85 = bVar1 << 1 ^ 0x1b;
if (-1 < (char)bVar1) {
local_85 = bVar1 << 1;
}
local_88 = 0;
if ((bVar2 & 2) != 0) {
local_88 = local_85;
}
local_8a = local_85 << 1 ^ 0x1b;
if (-1 < (char)local_85) {
local_8a = local_85 << 1;
}
local_8d = 0;
if ((bVar2 & 4) != 0) {
local_8d = local_8a;
}
local_8f = local_8a << 1 ^ 0x1b;
if (-1 < (char)local_8a) {
local_8f = local_8a << 1;
}
local_92 = 0;
if ((bVar2 & 8) != 0) {
local_92 = local_8f;
}
local_94 = local_8f << 1 ^ 0x1b;
if (-1 < (char)local_8f) {
local_94 = local_8f << 1;
}
local_97 = 0;
if ((bVar2 & 0x10) != 0) {
local_97 = local_94;
}
local_99 = local_94 << 1 ^ 0x1b;
if (-1 < (char)local_94) {
local_99 = local_94 << 1;
}
local_9c = 0;
if ((bVar2 & 0x20) != 0) {
local_9c = local_99;
}
local_9e = local_99 << 1 ^ 0x1b;
if (-1 < (char)local_99) {
local_9e = local_99 << 1;
}
local_a1 = 0;
if ((bVar2 & 0x40) != 0) {
local_a1 = local_9e;
}
local_a3 = local_9e << 1 ^ 0x1b;
if (-1 < (char)local_9e) {
local_a3 = local_9e << 1;
}
local_a6 = local_a3;
if (-1 < (char)bVar2) {
local_a6 = 0;
}
local_75 = local_7d ^ local_75 ^ local_88 ^ local_8d ^ local_92 ^ local_97 ^ local_9c ^
local_a1 ^ local_a6;
i = i + 1;
local_19 = local_75;
} while (i < width);
}
r0[local_20 + gid_x] = local_19 ^ ((char)gid_x + (char)gid_y);
VI - Putting everything together and meeting the maths
It took a bit of time to use the trace we generated in part IV and cross reference it with the decompilation of the main binary to understand how each transformation were used, but it was not too hard.
The most difficult part at this stage was to understand why some of those inputs were seemingly coming from nowhere. They were neither hardcoded as they differed from multiple traces with different inputs, but they didn’t seem to be coming from part of previous transormations either.
In the end I was able to reverse 3 functions, all based around the same concept of using some recursive SHA256 as a
sort of PRNG, responsible for these inputs. I named them sha256_tri_matrix, sha256_matrix and sha256_stream.
The most intresting one is sha256_tri_matrix as it used everytime the matrix multiplication is involved, generating a triangular
matrix ensure we will be able to find an inverse.
Once those functions were identified it was fairly easy to track were they were used, even when they were aggressively inlined by the compiler.
A few of them were using as a seed r[0] ^ g[100] ^ b[200], this is now the only unknown of our problem.
Well it’s time for bruteforcing.
256 possibilites is not a lot but as the script involves a lot of matrix multiplication and inversion it’s still pretty long, this is why I tried to make the bruteforce as late as possible by caching all the results not dependent on this seed beforehand.
VII - Conclusion
In the end this is my solve script:
import sys
import struct
from hashlib import sha256
import numpy as np
import galois
GF256 = galois.GF(256, irreducible_poly=0x11b)
def sha256_tri_matrix(seed, size):
state = bytes([seed] + [0]*0x1f)
state = sha256(state).digest()
out = [0] * (size*size)
x = 0
i = 0
while x < size:
y = x
while x < size:
if i == 8:
state = sha256(state).digest()
i = 0
out[y*size + x] = state[i*4]
i += 1
if x == y and out[y*size+x] == 0:
pass
else:
x += 1
x = y + 1
return out
def sha256_stream(seed, size, mask):
state = bytes([seed & 0xff] + [0]*0x1f)
state = sha256(state).digest()
out = [0] * size
j = 0
for i in range(size):
if j == 8:
state = sha256(state).digest()
j = 0
v = struct.unpack("I", state[j*4:(j+1)*4])[0] & mask
out[i] = v
j += 1
return out
def sha256_matrix(seed, size):
state = bytes([seed & 0xff] + [0]*0x1f)
state = sha256(state).digest()
out = list(range(size))
j = 0
for i in range(size, 0, -1):
if j == 8:
state = sha256(state).digest()
j = 0
idx = struct.unpack("I", state[j*4:(j+1)*4])[0]
j += 1
idx = idx % i
x = out[i - 1]
out[i - 1] = out[idx]
out[idx] = x
return out
def inv_prog3(r0, w1, op, n):
assert len(r0) == len(w1)
mask = (1 << n) - 1
w0 = [0] * len(r0)
for i in range(len(r0)):
if op == 0: # ADD
w0[i] = (r0[i] - w1[i]) & mask
elif op == 1: # SUB
w0[i] = (r0[i] + w1[i]) & mask
elif op == 2: # XOR
w0[i] = (r0[i] ^ w1[i]) & mask
elif op == 3: # ROL
s = w1[i] % n
x = ((r0[i] >> s) | (r0[i] << (n - s)))
w0[i] = x & mask
elif op == 4: # SHUF
w0[i] = r0[w1[i]]
return w0
# Reading the s-boxes directly from `spirv-dis` output
sboxes = []
with open("prog2.asm") as f:
for line in f.readlines():
if "OpConstantComposite %_arr_uchar_ulong_256" not in line:
continue
xs = line.strip().split(" ")[4:]
sboxes.append(list(map(lambda x: int(x.split("_")[1]), xs)))
sboxes_inv = b""
for sbox in sboxes:
sbox_inv = [None] * 0x100
for i in range(0x100):
sbox_inv[i] = sbox.index(i)
sboxes_inv += bytes(sbox_inv)
def inv_prog2(r0, sbox_id):
sbox_base = (sbox_id % 6) << 8
w0 = [0] * len(r0)
for i in range(len(r0)):
w0[i] = sboxes_inv[sbox_base + r0[i]]
return w0
def inv_prog1(r0, w1, width, height):
assert len(r0) == width * height
r0 = GF256(np.matrix(r0).reshape((width, height)))
global inv_matrix_cache
if type(w1) is int and w1 in inv_matrix_cache:
w1inv = inv_matrix_cache[w1]
else:
assert len(w1) == width * height
w1 = GF256(np.matrix(w1).reshape((width, height)))
print("w1inv...")
w1inv = np.linalg.inv(w1)
r0mask = GF256(np.matrix([[(x+y)&0xff for x in range(width)] for y in range(height)]))
print("w0...")
w0 = (r0 - r0mask) @ w1inv
return w0.flatten().tolist()
# There is probably a smarter way to do the inverse of a power in a GF but I have no idea how
# This is efficient enough for this situation
inv_pow_sboxes = b""
allowed_pow = b'\x01\x02\x04\x07\x08\x0b\x0d\x0e\x10\x13\x16\x17\x1a\x1c\x1d\x1f' + \
b'\x20\x25\x26\x29\x2b\x2c\x2e\x2f\x31\x34\x35\x38\x3a\x3b\x3d\x3e' + \
b'\x40\x43\x47\x49\x4a\x4c\x4d\x4f\x52\x53\x56\x58\x59\x5b\x5c\x5e' + \
b'\x61\x62\x65\x67\x68\x6a\x6b\x6d\x70\x71\x74\x76\x79\x7a\x7c\x7f' + \
b'\x80\x83\x85\x86\x89\x8b\x8e\x8f\x92\x94\x95\x97\x98\x9a\x9d\x9e' + \
b'\xa1\xa3\xa4\xa6\xa7\xa9\xac\xad\xb0\xb2\xb3\xb5\xb6\xb8\xbc\xbf' + \
b'\xc1\xc2\xc4\xc5\xc7\xca\xcb\xce\xd0\xd1\xd3\xd4\xd6\xd9\xda\xdf' + \
b'\xe0\xe2\xe3\xe5\xe8\xe9\xec\xef\xf1\xf2\xf4\xf7\xf8\xfb\xfd\xfe'
for p in allowed_pow:
box = [0] * 256
for x in range(256):
y = GF256(x) ** p
box[y] = x
inv_pow_sboxes += bytes(box)
def inv_prog1_pow(r0, p):
w0 = [0] * len(r0)
for i in range(len(r0)):
x = r0[(i - p) % len(r0)]
w0[i] = inv_pow_sboxes[(p&0x7f)*0x100 + (x ^ 0xab)]
return w0
# A bunch of utility functions used to easily convert u8 matricies to u32 and u16 ones
def as_u16(xs):
r = [0] * (len(xs)>>1)
for i in range(len(xs)>>1):
r[i] = xs[i<<1] | (xs[(i<<1) + 1]<<8)
return r
def as_u32(xs):
r = [0] * (len(xs)>>2)
for i in range(len(xs)>>2):
r[i] = xs[i<<2] | (xs[(i<<2) + 1]<<8) | (xs[(i<<2) + 2]<<16) | (xs[(i<<2) + 3]<<24)
return r
def u16_to_u8(xs):
r = [0] * (len(xs)<<1)
for i in range(len(xs)):
r[i<<1] = xs[i] & 0xff
r[(i<<1)+1] = xs[i] >> 8
return r
def u32_to_u8(xs):
r = [0] * (len(xs)<<2)
for i in range(len(xs)):
r[i<<2] = xs[i] & 0xff
r[(i<<2)+1] = (xs[i] >> 8) & 0xff
r[(i<<2)+2] = (xs[i] >> 16) & 0xff
r[(i<<2)+3] = xs[i] >> 24
return r
# We precalculate the inverse matricies we will use multiple times
inv_matrix_cache = {}
for i in range(0x10):
w1 = sha256_tri_matrix(i, 0x100)
w1 = GF256(np.matrix(w1).reshape((0x100, 0x100)))
print("w1inv", i)
w1inv = np.linalg.inv(w1)
inv_matrix_cache[i] = w1inv
w1 = sha256_tri_matrix(0x59, 0x400)
w1 = GF256(np.matrix(w1).reshape((0x400, 0x400)))
print("w1inv 0x59")
w1inv = np.linalg.inv(w1)
inv_matrix_cache[0x1059] = w1inv
w1 = sha256_tri_matrix(0xb, 0x400)
w1 = GF256(np.matrix(w1).reshape((0x400, 0x400)))
print("w1inv 0xb")
w1inv = np.linalg.inv(w1)
inv_matrix_cache[0x100b] = w1inv
def prog_r(r0, seed):
assert len(r0) == 1024*1024
print(bytes(r0[:32]).hex())
r0 = u16_to_u8(inv_prog3(as_u16(r0), sha256_stream(0x11, 0x80000, 0xffff), 3, 16))
print(bytes(r0[:32]).hex())
r0 = inv_prog1(r0, sha256_tri_matrix(seed, 0x400), 0x400, 0x400)
print(bytes(r0[:32]).hex())
r0 = inv_prog2(r0, 0x1337)
print(bytes(r0[:32]).hex())
r0 = u32_to_u8(inv_prog3(as_u32(r0), sha256_matrix(seed * 10, 0x40000), 4, 32))
print(bytes(r0[:32]).hex())
r0 = inv_prog1(r0, 0x100b, 0x400, 0x400)
print(bytes(r0[:32]).hex())
return r0
def prog_g_p1(r0):
assert len(r0) == 1024*1024
print(bytes(r0[:32]).hex())
r0 = inv_prog1(r0, 0x1059, 0x400, 0x400)
print(bytes(r0[:32]).hex())
m3 = sha256_matrix(0x40, 0x80)
r0_next = []
for i in range(len(r0)//0x80):
r0_next += inv_prog3(r0[i*0x80:(i+1)*0x80], m3, 4, 8)
r0 = r0_next
print(bytes(r0[:32]).hex())
m3 = sha256_matrix(0x82, 0x8000)
r0_next = []
for i in range(len(r0)//0x10000):
r0_next += u16_to_u8(inv_prog3(as_u16(r0[i*0x10000:(i+1)*0x10000]), m3, 4, 16))
r0 = r0_next
print(bytes(r0[:32]).hex())
r0 = u32_to_u8(inv_prog3(as_u32(r0), sha256_stream(0x67, 0x40000, 0xffffffff), 3, 32))
print(bytes(r0[:32]).hex())
return r0
def prog_g_p2(r0, seed):
r0 = inv_prog1_pow(r0, seed * 2)
print(bytes(r0[:32]).hex())
r0 = inv_prog1_pow(r0, seed)
print(bytes(r0[:32]).hex())
r0 = inv_prog1_pow(r0, 0)
print(bytes(r0[:32]).hex())
return r0
def prog_b_p1(r0):
assert len(r0) == 1024*1024
print(bytes(r0[:32]).hex())
r0 = u16_to_u8(inv_prog3(as_u16(r0), sha256_stream(0xbb, 0x80000, 0xffff), 2, 16))
print(bytes(r0[:32]).hex())
r0a = inv_prog3(r0[:0x80000], sha256_stream(0x12, 0x80000, 0xff), 0, 8)
r0b = u32_to_u8(inv_prog3(as_u32(r0[0x80000:]), sha256_stream(0xaa, 0x20000, 0xffffffff), 1, 32))
r0 = r0a + r0b
print(bytes(r0[:32]).hex())
shuffle = b'\x0d\x02\x0c\x08\x06\x05\x01\x09\x04\x0f\x0a\x0b\x07\x00\x03\x0e'
r0n = []
for i in range(0x10):
idx = shuffle[i]
xs = inv_prog1(r0[idx*0x100*0x100:(idx+1)*0x100*0x100], i, 0x100, 0x100)
print(bytes(xs[:32]).hex())
r0n += xs
r0 = r0n
print(bytes(r0[:32]).hex())
return r0
def prog_b_p2(r0, seed):
for i in range(0x20):
r0 = inv_prog2(r0, (0x1F - i) * seed)
print(bytes(r0[:32]).hex())
return r0
# We read the expected output
rr0 = [None] * (1024*1024)
gr0 = [None] * (1024*1024)
br0 = [None] * (1024*1024)
with open("kraken", "rb") as f:
f.seek(0xce68)
for i in range(1024*1024):
rgb = f.read(3)
rr0[i] = rgb[0]
gr0[i] = rgb[1]
br0[i] = rgb[2]
# Green and blue channels are splited in 2 "parts"
# The first one can be computed ahead of time as it doesn't require the correct seed
# The second one will be recalculated on each try of the bruteforce
g_p1 = prog_g_p1(gr0)
b_p1 = prog_b_p1(br0)
print("")
print("PREPWORK DONE - BRUTEFORCING SEED")
for seed in range(0x100):
print("")
g = prog_g_p2(g_p1, seed)
b = prog_b_p2(b_p1, seed)
r = prog_r(rr0, seed)
print(seed)
if r[0] ^ g[100] ^ b[200] == seed:
print("GOOD SEED FOUND")
open("r.bin", "wb").write(bytes(r))
open("g.bin", "wb").write(bytes(g))
open("b.bin", "wb").write(bytes(b))
sys.exit(0)
As it is single-threaded, I took my usual “lazy multi-threading” approch by launching two of them, one on the range [0;127] and the other on [128;255].
After 45 minutes they both finish, and this is when you notice that you forgot the catch in c that was offseting the results by p. -_-
After noticing and fixing this issue we are able to find the correct seed 0x2c and to reconstruct the input image:

$ ./kraken input.ppm
[+] OK: loaded input.ppm
[+] OK! The flag is: FCSC{54fdbee77db853ec2fa844398a9fb460a8623d81cbef4056dbdd0b7bcf03ffbe}
There is probably a way to make it more granular by only allowing the required capabilities, but I was too lazy. ↩︎